作为人工智能界的翘楚,科大讯飞面对当前的业态,正在思考用户对智能座舱是什么样的期待,主机厂对他们又是什么样的期待,他们如何把好的技术应用到座舱的空间中。就这些问题,田雨分享了他对AI助力智能座舱的升级的观点。

科大讯飞股份有限公司智能座舱产品线总监田雨
赋能座舱:科大讯飞得天独厚
截止至2021年10月,科大讯飞共夺得38项国际人工智能大赛冠军。其中包括:由著名的语言数据联盟(LDC)于2018年发起的DIHARD,被誉为该领域最“困难的”挑战赛。2021年1月,科大讯飞获得2021年国际说话人角色分离比赛DIHARD-3冠军。
2021年8月,科大讯飞凭借在道路目标检测领域多年的技术探索,刷新了Cityscapes 3D目标检测任务的全球最好成绩,得到检测分数42.9。是科大讯飞继2017年、2018年参与测评之后,第三次参加Cityscapes比赛并刷新世界纪录。
2020年CHiME-6科大讯飞再次以显著优势获得冠军,大幅刷新了该项赛事历史最好成绩。面向万物互联时代语音交互等真实场景下的语音识别任务,通过算法创新将错误率从46.1%降低到30.5%。
科大讯飞作为汽车智能化领域的先行者,自2003年开始,深耕汽车智能化领域,使人工智能技术在汽车产品上得到了深度应用。目前合作已覆盖90%以上的中国自主品牌和合资品牌车厂,累计前装搭载量突破 3600万套。
智能交互:从语音命令到自然交互
谈到交互,其本质就是信息的输入和输出,人有五感,包括了听、嗅、看、闻和触觉,其中信息的输入靠的是听觉,信息的输出主要靠语言。
将信息交互的过程放到车内可以看到,从感知对应听和看,经过了认知,个人进行理解,最终通过说和显示进行表达出来。所以交互可以归纳成听、说、看、显四个核心的技术。科大讯飞结合视觉,把看和显示进行补齐,就有了多模的=交互,加上视觉以后有更多想象的空间。
有了听、说、看、显的技术之后,用户还需要结合一个一个的场景进行交互的设计,所以就成为了交互管理。

引入多模,科大讯飞也有了如下几个提升点:
第一,实现驾驶员和乘客的人员分布的检测,可以知道车上有几个人,大家都在什么位置,这样可以实现所谓的分区的交互。每个座位上的每个乘客或者驾驶员都有自己个性化的交互诉求,让交互更加个性。
第二,更好的多模语音的分离。在高噪的场景下,结合视觉,去检测口唇,让识别率在高噪的环境下变得可用。在实时体验时,在真正高速、高噪的情况下副驾不一定听清楚什么样的指令,但是结合多模视觉就可以听音识别。
第三,做到情绪的感知,通过图像,包括语言、文字、内容的理解对车路路政这样的场景可以做很好的识别,目前识别率基本上达到了95%。
第一代的合成引擎发展到XTTS1、2、3,目前到3.0的状态,已经是非常自然的听感。从业务上看,一方面对语种,包括方言的合成,科大讯飞明年可以适应30个国家的语种,这样对自主品牌去走向世界出海的需求得到满足。
此外,科大讯飞正在进行运营方式上的探索,部署个性化TTS的合成。在TTS引擎里面加入情感化的因素,包括语气、语调,能够反映出人物性格的一种音色,通过声音商城的方式,用用户在线订阅的方式进行交互。
如何达到自然交互,其涉及到一系列技术体系的创新和融合。首先要解决噪声环境下要对口音,包括语言的发声友好,支持强噪声下不同方言的口音,让引擎也可以支持方言和普通话的免切换。其次是情绪合成,在自然对话过程中对语义进行更好的理解。最后在自然对话的过程中,人和人之间的交流是带着上下文的场景,要让交互就算放到上下文的语境里面去也可以得到支持。
目前科大讯飞在180多个场景里融合了以上的交互技术。
此外,想要打造情感有很多方式,科大讯飞认为人设是其中的一条路线,对于人设来讲,除了人物的形象,还包含了肢体动作以及微表情,有了这些技术之后再和用户产生互动,能够最好的刺激用户,让用户产生所谓的情感连接。这部分是讯飞视觉技术的应用,其基于视线的检测,包括DMS的功能,在车内的应用以及相当成熟。
田雨认为:从交互层面而言,过去是单点语音播报,现在通过虚拟助手带形象的人物,融合了多模交互的能力,让汽车交互更加有趣和自然。
智能声场:从播放声音到听享空间
车内座舱目前发生了很大的变化,包括越来越多的屏幕,越来越多的智能化部件。但从车内声音角度来说,其实这么多年并没有发生实质的改变。
目前用户对座舱的声音有了新需求:
第一个是在座舱的听感一定要变得更加舒适,听感的享受要变得更强。第二是在座舱内要有更多个性化的交互和分区的交互,让座舱能让大家听的更加个性。第三是座舱能主动对用户进行一些关怀。第四是在驾驶过程中,个性化的满足。
基于这些的思考,科大讯飞打造座舱内的听响空间,包括360度的环绕立体声,把真实的现场还原到车内;结合多音区的交互,打造VRP的专属听感。
在落地方面,科大讯飞经过三年的努力,3D环绕声算法已经研制完成,在忙听的测试中,各项指标都优于行业的头部精品,同时主观的听感也优于其他企业。同时,科大讯飞也在研究主动降噪的算法,在隐性的噪声降噪中,目前可以达到20db的峰值,降噪的幅度也可以从20赫兹-500赫兹。业界现在最好的算法降噪幅度也是300赫兹,但科大讯飞可以做到500赫兹。此外,其正在研究车内通信的交流补偿技术,在一些高配的车上已经提供了这种功能。
科大讯飞在做语音行业里面,降噪技术一直处于业内头部,在录音识别完以后将声音消除干净。另外对音效的把控力也是行业前列,在很准确的方位上把它进行呈现,也不用像现在的技术,要在整车内进行还原,而且播放出来的声音也不会有其他干扰,这样的技术让整车的声音有更好的体现。
视觉上有黄金分割点,其实在听觉空间里也存在这样的位置,在车内的听觉感受之所以不好,是因为没有把用户放到这样一个黄金点位上。现在有了多模的视觉,就可以精准的捕捉到用户在哪,它的最佳位置在哪里,打造听觉皇帝位。做到用户在哪,哪里就是皇帝位。当视觉寻找到用户在哪,然后动态进行音效的调节,可以让听感变的很好。当引入了多模的皇帝位的设计后,一定能够提升在车内的最佳听感。

智能服务:从提供功能到全程服务
科大讯飞认为服务升级未来会有三个方向,第一是服务主动化,服务如果不够主动就不能称之为服务,服务就需要被用户去调用和索取。如何做到服务的主动化,如何在用户困难时递一个枕头让他们这么舒适,这需要结合到第二个方向——服务场景化,真正去结合一个细分的场景去提供所谓主动的服务。第三个方向即服务个性化。
要做到这样的服务升级,就离不开核心内容,即场景平台,又或是场景引擎。无论是车端数据,还是环境数据,包括用户的数据。在感知到场景平台之后,进行数据的处理,经过场景模型和业务配置,分发到不同的端,包括车机、手机和智能家居进行智能推荐决策。
感知数据包含了用户的数据和车的数据,有车内的车外的以及用户行为的数据。本身这些数据一方面是响应对数据合规的要求进行隐私化保护,另外是在技术架构方面也会利用好边缘计算能力,把更多的车身和用户本身数据在本地处理好,去达到用户隐私保护的效果。
有了数据之后,就涉及到场景。从整个大的场景闭环来看,用户由新手到慢慢成长为老司机,从上车、行车、到达到停车都会有一系列的细分场景,之后去提供对应的服务。这种服务被称为基础的探针服务,结合每一次用户的具体反馈,需要那样形式的呈现时,就会把它变成各种个性化的服务。除此之外,科大讯飞也为主机厂提供了完善的工具链,在云端有场景的配置平台,能够快速的定制和模拟场景的效果。
对于车主而言真正和车相关和用车相关的能力,还比较欠缺。以往在遇到这些问题时,首要选择是打电话进行厂外求助,科大讯飞正在探索一种方式让这些服务都融合到车内,围绕整个购车的周期旅程,其设计了如下的产品功能:
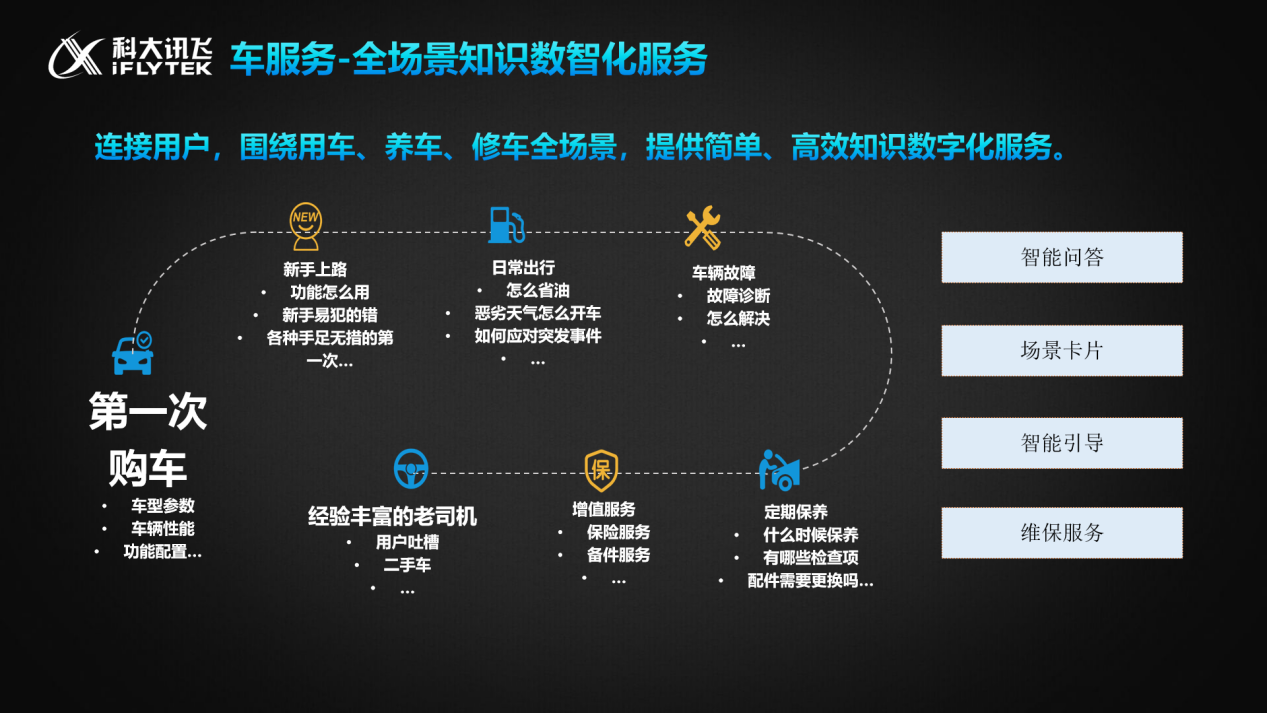
第一是去吸收厚厚的几本手册,一辆车以前都会有很厚的说明书,科大讯飞通过阅读理解把知识进行结构化的抽取,通过知识图谱的构建,在前端通过交互技术,以智能问答的形式,找答你所问,
第二是把整个用车生命周期中的高频场景进行了提炼。对应的会呈现知识锦囊,雨天行车、新手上路,这些场景的用户可能会遇到什么样的问题,需要什么样的服务都提前准备好。
第三是智能引导,解决用户的学习成本和感知的问题。当一个新手在开了两次高速之后,第三次上高速就会高速他,有一个功能其实和这个场景非常匹配,此时用户自然而然的能在场景里使用对应功能,然后真正的实现产品的价值。
如此服务至少有两个层面的好处,第一个可以切实解决用户在用车过程中的问题。第二点是反向对产品的设计人员可以第一时间连接到用户的想法,反过来可以对产品进行更好的改进。
田雨从三方面阐述了科大讯飞对于智能座舱的思考,利用AI的好技术,让座舱在交互空间和服务上全面升级,让整个智能驾驶出行达到更加的安全、智能、具有乐趣的目的。









